
ChatGPT를 활용한 Node.js API 개발 (2)
LangChain.js
이전 글에서 설명했던 대부분의 코드는 LangChain.js(이하 랭체인)의 재발명이었다. 복잡하고 귀찮은 대부분의 작업들을 랭체인을 통해서 간단하게 처리할 수 있다. 아마 이전 글에서 설명한 부분을 직접 구현해본 경험이 있는 사람이라면, 해당 부분을 구현하면서 “분명히 누군가 짜놨을 것 같긴한데…” 했을 것이다. 나 역시 “뭐 어려운 것도 아니고 그냥 구현하지~” 하고 시작했으나, 후회하고 있다. 물론 랭체인을 쓰지 않고도 LLM을 이용한 어플리케이션을 개발할 수 있다. 마치 유틸리티 함수를 만들거나 활용하지 않고 프로그램을 완성하는 것과 같은 느낌으로..
2023.6.13 OpenAI Patch

위 패치 덕분에 같은 프롬프트가 처리되는 데에 소요되는 시간이 절반 가까이 줄었다. 해당 패치를 통해 더 많은 토큰을 한 번에 처리할 수 있는 모델들도 공개되었다. OpenAI를 이용하여 어플리케이션을 만든다고 하는 것은 외부 서비스에 강하게 의존한다는 것과 동치이기에, OpenAI의 업데이트 소식을 계속 받아보는 것이 중요하겠다.
Rate Limit
당연하지만 OpenAI의 API에는 Rate Limits가 있다. Rate Limit은 꽤 자주 변한다. (내가 알던 값이랑 현재 위 페이지에 기재된 값이 다르다..!) API 호출 결과에 usage를 보면 prompt_tokens 와 completion_tokens 값이 있고, 두 값을 더한 값이 내 토큰 사용량이 되며, 이 값은 사용하는 언어 모델(e.g. gpt-3.5-turbo, text-davinci-003 등)에 따라 달라지니 유의해야 한다.
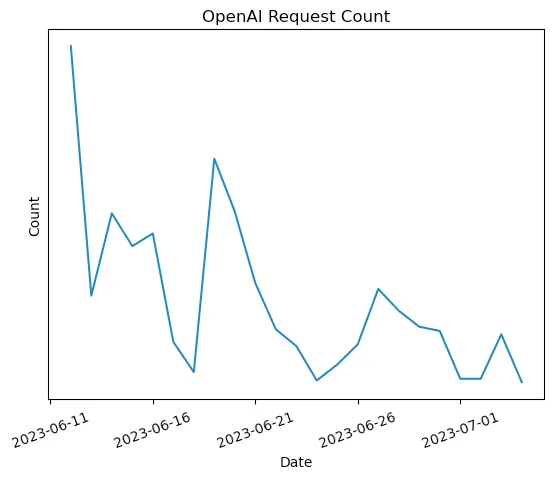
위 이미지는 정확한 값을 제외하고 6/10쯤 부터 최근까지 서버에서 OpenAI로 보낸 API 요청수(Request Count)의 추세를 나타낸 그래프다. ChatGPT를 이용한 피쳐를 배포한 초반에 요청이 상대적으로 많은 것을 확인할 수 있다. 요청이 많을 수록, 그리고 짧은 시간에 요청이 몰릴 수록 한도를 넘어서게 되고, 429 Too Many Requests 에러를 만날 수 있다. 다음 그래프는 피쳐 배포 이후에 서버에 찍힌 에러 로그다.
| date | status | statusText |
|---|---|---|
| 20230614 | 429 | Too Many Requests |
| 20230614 | 429 | Too Many Requests |
| 20230614 | 429 | Too Many Requests |
| 20230616 | 429 | Too Many Requests |
| 20230616 | 429 | Too Many Requests |
| 20230616 | 429 | Too Many Requests |
| 20230616 | 429 | Too Many Requests |
| 20230616 | 429 | Too Many Requests |
| 20230617 | 429 | Too Many Requests |
| 20230619 | 429 | Too Many Requests |
| 20230619 | 429 | Too Many Requests |
| 20230619 | 429 | Too Many Requests |
| 20230619 | 502 | Bad Gateway |
| 20230619 | 502 | Bad Gateway |
| 20230619 | 503 | Service Unavailable |
| 20230620 | 429 | Too Many Requests |
| 20230620 | 429 | Too Many Requests |
| 20230620 | 429 | Too Many Requests |
| 20230620 | 429 | Too Many Requests |
| 20230625 | 503 | Service Unavailable |
| 20230626 | 502 | Bad Gateway |
| 20230626 | 503 | Service Unavailable |
| 20230629 | 401 | Unauthorized |
| 20230629 | 401 | Unauthorized |
| 20230629 | 503 | Service Unavailable |
| 20230630 | 503 | Service Unavailable |
| 20230630 | 503 | Service Unavailable |
429 에러를 만났을 때 할 수 있는 방법은 총 3가지 정도 있다.
-
새로운 계정을 만들고, 새로운 Organization과 새로운 API Key를 발급받아서, OpenAI 객체 두 개를 활용하면 된다. 단순 계산으로 Quota는 두 배가 된다.
-
MS Azure에서 서비스하는 OpenAI를 사용한다.
1번이 가장 빠르다. 2번은 아직 답이 없다. 3-1은 빠르다. 3-1까지 하면 gpt-3.5-turbo의 0301 snapshot만 쓸 수 있다. latest snapshot은 사용할 수 없다. 3-2는 아직까지 답이 없다. MS Azure는 분당 240,000 token의 요청을 처리하니 1번을 적용한 뒤라면 굳이 애져까지.. 라는 생각이 들 수도 있다. 계산을 해본 뒤 애져 서비스에 대기열을 등록하자.
429 에러 외에도 502, 503과 같은 OpenAI의 서버가 불안정한 현상도 종종 확인할 수 있었고, 무엇보다 401과 같이 api_key의 유출이 의심된다며 새로 발급받으라는 메일이 날아온 경우도 있었다. 결제를 재무팀에 부탁했더라도, 이메일은 개발자가 받을 수 있게 하자.
Stress Test
Rate Limit이 얼마나 걸릴지 어떻게 알 수 있을까. 우리는 스트레스 테스트를 해야한다.
ab -c100 -n1000 -v4 -p body.json -T application/json "http://localhost:4005/api/..."macOS에 기본적으로 설치된 Apache HTTP Server Benchmarking Tool, “ab”를 사용하여 스트레스 테스트를 진행하고, 1분 당 어느정도의 리퀘스트를 처리할 수 있는지 확인하자. 예상 사용량이 이 값보다 높으면 위에서 소개한 방법을 사용하거나, Latency가 중요하지 않으면 Queue를 사용하면 된다.
Latency
그렇다. Latency는 생각보다 중요하다. OpenAI Web UI에서 사용하는 것과 실제로 API에서 느껴지는 Latency는 꽤 차이가 난다. (2023/6/13 업데이트 이후로는 조금 덜 난다.) 따라서, 이를 감당 가능한 수준으로 프롬프트를 조절해야한다. 광고 제목 5개 생성 프롬프트를 처리하던 것을, 광고 제목 3개 생성 프롬프트를 처리하는 것으로 바꾸면 소요되는 시간은 3/5만큼 짧아진다. 주어진 프롬프트가 조금 더 단순해질 수록 미세하게 소요 시간이 짧아진다. 타겟 언어를 영어로 하면 10~20%정도 짧아진다.
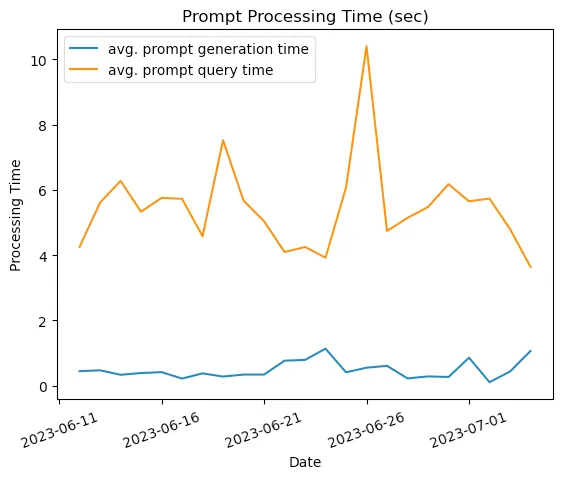
위 그래프에서 generation time(파란색)은 데이터베이스로부터 과거 데이터를 조회해서 프롬프트를 생성하는데 걸린 시간이고, query time(주황색)은 생성된 프롬프트를 OpenAI API 요청을 처리하는데 걸린 시간이다. 6/26쯤 그래프를 보면 이 값이 생각보다 들쭉날쭉한 것을 확인할 수 있다. Latency가 대단히 중요한 어플리케이션을 만든다면, LLM으로 OpenAI를 선택하는 것은 위험할 수 있다.